
Database초보우낙
3. 12c 버젼 이후부터 반드시 챙겨야하는 SQL튜닝 관련 파라미터 본문
db 엔지니어와 dba가 오라클을 12c 이후 버젼부터 설치를 한 후에 반드시
변경여부를 확인해야하는 SQL튜닝 파라미터가 무엇인가요 ?
답: optimizer_adaptive_reporting_only 파라미터 (12C 뉴피쳐)
입력되는 데이터의 구성에 따라서 같은 SQL의 실행계획이 실시간 변경되는 기능
일반적으로 현장에서는 SQL의 실행계획이 잘 변경되지 않고 그대로 유지되기를
원합니다.
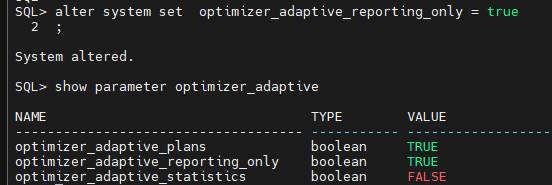
문제1. optimizer_adaptive_reporting_only 가 어떻게 셋팅되어있는지 확인합니다.

false 가 활성화이고 true 가 비활성화 입니다.
설명: OPTIMIZER_ADAPTIVE_REPORTING_ONLY 파라미터의 기본값은 FALSE입니다.
이 값이 FALSE로 설정되어 있을 때는, 데이터베이스가 실행 시간에 수집한 통계를 바탕으로
실행 계획을 자동으로 조정할 수 있습니다. 반면, 이 값을 TRUE로 설정하면, 최적화를 위한 정보는 수집되지만 실행 계획에는 어떠한 변경도 적용되지 않는 보고 전용 모드로 전환됩니다
이 파라미터를 이해하려면 아래의 내용이 복습이 되어야합니다.
1. (면접문제) select 문의 처리과정
2. 옵티마이져에게 영향을 주는 요소들
3. dynamic sampling 기능 -------------------------> 위의 기능입니다.
업그레이드
■ 1. (면접문제) select 문의 처리과정이 어떻게 되나요?
답변: 1. parsing : SQL 문장의 문법검사와 의미검사를 해서 기계어를 생성
기계어(parse tree) 와 실행계획이 이 단계에서 만들어집니다.
2. execute : 검색하고자 하는 데이터를 찾는 과정
찾을 때 메모리인 SGA 영역의 버퍼캐쉬에서 먼저 찾고 없으면
data file 에서 찾아서 버퍼캐쉬로 올립니다.
3. fetch : 서버쪽의 서버 프로세서가 결과물을 클라이언트의 유져 프로세서에게
전달하는 과정
옵티마이져란 ? 실행계획을 생성하는 오라클 프로세서 입니다.
옵티마이저가 실행계획을 생성할 때 관련된 SQL의 통계정보가 있는지 조회하고 있으면 그 통계정보를 보고 실행계획을 생성합니다
문제1. EMP 테이블의 통계정보가 수집되었는지 확인하세요
select table_name, last_analyzed
from user_tables
where table_name = 'EMP';
설명 : num_rows는 테이블 건수이고 avg_row_len은 평균 행의 길이
문제2. emp테이블에 대해서 테이블 통계정보를 수집하세요
exec dbms_stats.gather_table_stats('SCOTT','EMP');
select table_name, last_analyzed , num_rows,avg_row_len
from user_tables
where table_name = 'EMP';
테이블 통계정보를 수집하는 이유는?
->옵티마이저가 보다 더 좋은 실행계획을 생성하기 위해서 필요합니다.
옵티마이저에 영향을 주는 요소들이 뭐가 있는가?
-> 테이블 통계정보
-> 옵티마이져와 관련된 오라클 파라미터
-> 오라클 버전
다이나믹 샘플링기능 -------------------------->실시간 실행계획 변경 기능
문제. optimizer_adaptive_reporting_only를 true로 변경하세요
alter system set optimizer_adaptive_reporting_only = true
문제.optimizer_adaptive_reporting_only를 false로 변경하세요
alter system set optimizer_adaptive_reporting_only = false

DB를 내렸다가 올리기
startup force
#1. 메모리의 내용을 모두 flush시킵니다 <깔끔하게 실습하기 위해서 짆행>
#공유풀에 올라온 데이터를 지웁니다.
alter system flush shared_pool;
#버퍼캐쉬에 올라온 데이터를 다 지웁니다.
alter system flush buffer_cache;
#현업에서는 ORA-4031에러가 날때만 위의 명령어를 수행
#지금은 테스트를 해보려고 수행하는 것

drop table stage;
drop table t1;
drop table t2;
drop table t3;
drop table t4;
#. 테스트할 테이블을 생성하고 데이터를 입력합니다
-- stage 테이블 생성
CREATE TABLE stage (
object_id NUMBER);
-- 테이블 데이터 적재
-- 여기서는 단순히 임의의 데이터를 생성하여 적재하겠습니다.
INSERT INTO stage (object_id)
SELECT LEVEL
FROM DUAL
CONNECT BY LEVEL <= 10000; -- 적재할 데이터의 행 수에 맞게 조정합니다.
#조인 SQL문장을 작성할 테스트 테이블 4개를 생성합니다
create table t1 as select * from stage;
insert into t1 select * from t1;
create table t2 as select * from stage;
insert into t2 select * from t2;
create table t3 as select * from stage;
insert into t3 select * from t3;
create table t4 as select * from stage;
insert into t4 select * from t4;
#인덱스를 생성
create index t1_idx on t1(object_id);
create index t2_idx on t2(object_id);
create index t3_idx on t3(object_id);
create index t4_idx on t4(object_id);
select * from t1;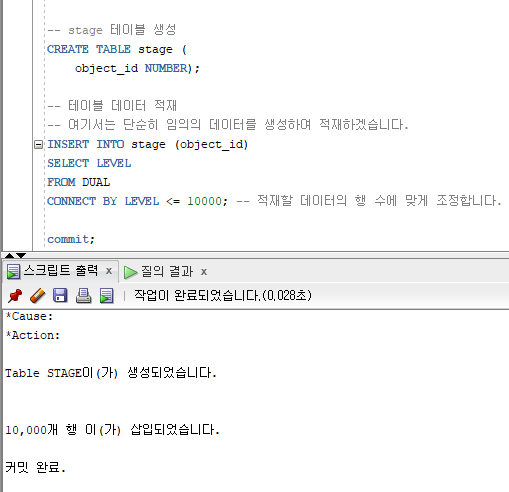

#테이블 통계정보를 수집
exec dbms_stats.gather_table_stats( user, 'T1' );
exec dbms_stats.gather_table_stats( user, 'T2' );
exec dbms_stats.gather_table_stats( user, 'T3' );
exec dbms_stats.gather_table_stats( user, 'T4' );
#조인문장을 실행
select /*+ gather_plan_statistics */ *
from t1, t2, t3, t4
where t1.object_id = t2.object_id+1
and t2.object_id = t3.object_id+1
and t3.object_id = t4.object_id+1
and t4.object_id = 42;
select sql_id, child_number, sql_text
from v$sql
where sql_text like '%t1%' AND sql_text NOT LIKE '%v$sql%'
ORDER BY last_load_time DESC;
SELECT * FROM TABLE(dbms_xplan.display_cursor('1tgz4ay5q9781', 0,'ALLSTATS LAST'));
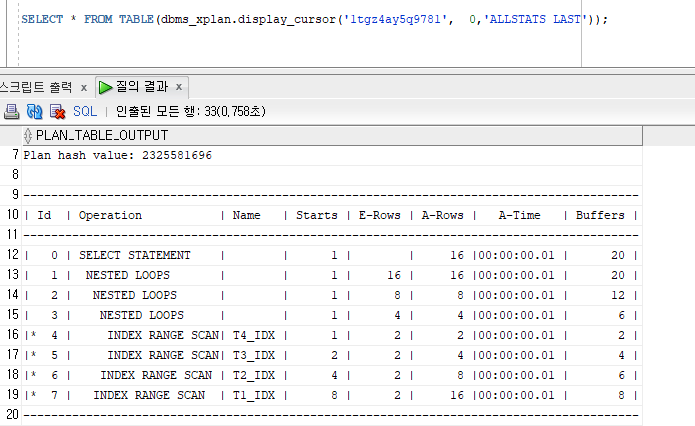
모두 Nested Loop join을 하였다.
#다음과 같이 데이터를 변경하세요
update t1 set object_id = 42 ;
update t2 set object_id = 42 ;
update t3 set object_id = 42 ;
update t4 set object_id = 42 ;
commit; 테이블의 모든 데이터를 전부 같은 값으로 변경을 하게 되면 인덱스가 있지만
full table scan하는 실행계획이 더 유리하고 full table scan이면 nested loop 조인보다는 hash 조인이 더 유리하다
select /*+ gather_plan_statistics */ *
from t1, t2, t3, t4
where t1.object_id = t2.object_id+1
and t2.object_id = t3.object_id+1
and t3.object_id = t4.object_id+1
and t4.object_id = 42;
select sql_id, child_number, sql_text
from v$sql
where sql_text like '%t1%' AND sql_text NOT LIKE '%v$sql%'
ORDER BY last_load_time DESC;
SELECT * FROM TABLE(dbms_xplan.display_cursor('1tgz4ay5q9781', 2,'ALLSTATS LAST'));
위의 실행계획중에 하나의 조인방법이 HASH 조인으로 나오면서 실행계획이 변경이
됩니다.
정리:
설명: OPTIMIZER_ADAPTIVE_REPORTING_ONLY 파라미터의 기본값은 FALSE입니다.
이 값이 FALSE로 설정되어 있을 때는, 데이터베이스가 실행 시간에 수집한 통계를 바탕으로
실행 계획을 자동으로 조정할 수 있습니다. 반면, 이 값을 TRUE로 설정하면, 최적화를 위한 정보는 수집되지만 실행 계획에는 어떠한 변경도 적용되지 않는 보고 전용 모드로 전환됩니다
SQL튜닝에 대한 전문가가 많지 않은 데이터 베이스 환경에서는 OPTIMIZER_ADAPTIVE_REPORTING_ONLY 를 True 로 변경하는게 바람직합니다.
'oracle 12c' 카테고리의 다른 글
| 6. 컬럼값 자동증가 기능(12c 뉴피처) (0) | 2024.04.26 |
|---|---|
| 5. 페이징 처리가능 (12c 뉴피처) (1) | 2024.04.26 |
| 4. 같은 컬럼에 여러개의 인덱스를 생성할 수 있다(12c) (0) | 2024.04.26 |
| 2.(새로운 오라클 기능 1) 보이지않는 컬럼 (0) | 2024.04.26 |
| 1. 21c db환경설정 (0) | 2024.04.26 |



