20. cancel base 불완전 복구
복구의 종류 2가지
- 완전복구 --- 장애가 나기 직전에 최종적으로 commit한 시점으로 복구하는 것
- 불완전 복구 ---과거의 특정 시점으로 복구

current redo log file이 깨져서 db가 shutdown되었다면 복구하는 방법이 과거에 백업받은 모든 data file들을 다 복원하고 아카이브 로그 파일을 적용해서 복구를 하는데 current redo log file 까지 적용해야 완전 복구가 되는데 current redo log file이 없으므로 cancel base 불완전 복구를 해야한다
current redo log file만 적용안하고 cancel하겠다는 의미
■ 실습
#1. cold backup 수행
#2. 로그 스위치를 3번 일으키고 체크포인트를 일으킨다
#3. 깨트릴 current redo log file을 확인
#4. current redo log group의 멤버를 확인
#5. shutdown abort
#6. os에서 current redo log group의 멤버를 모두 삭제
#7. startup <------mount단계에서 멈추는것을 확인
#8. 문제가 되는 redo log file의 현재 상태가 무엇인지 확인
#9.shutdown abort
#10. 모든 data file들을 복원(기존 원본 data file들은 rm으로 지우고 복원, 안지우고 복원하면 안되는 파일들이 있음)
#11. startup mount
#12. set autorecovery off <------- 복구할 때 적용해야할 로그 파일을 하나씩 물어보게 설정
#13 . recover database until cancle;
엔터를 치다가 current redo log file을 적용하려할때 cancel 을 입력
#14. resetlogs 옵션을 써서 open을 시킨다
◆ 구현 ----> Ouh 계정에서 진행
#1. cold backup 수행
@datafile
@controlfile
@logfile--모든 파일이 같은곳에 위치해야한다

<sys>
shutdown immediate
<os>
cd
mkdir coldbackup5
cd coldbackup5
cp /u01/app/oracle/oradata/Ouh/* .
<sys>
startup
#2. 로그 스위치를 3번 일으키고 체크포인트를 일으킨다
@logsw
@logsw
@logsw
alter system checkpoint
#3. 깨트릴 current redo log file을 확인

@log_status
#4. current redo log group의 멤버를 확인
@logfile
#5. DB를 내린다
shutdown abort
#6. os에서 current redo log group의 멤버를 모두 삭제
#7. startup <------mount단계에서 멈추는것을 확인

#8. 문제가 되는 redo log file의 현재 상태가 무엇인지 확인

ORA-00312: online log 1 thread 1:
#9. DB를 내린다
shutdown abort
#10. 모든 data file들을 복원(기존 원본 data file들은 rm으로 지우고 복원, 안지우고 복원하면 안되는 파일들이 있음)
oradata
ls
rm *.dbf
cp /home/oracle/coldbackup5/*.dbf .
#11. startup mount
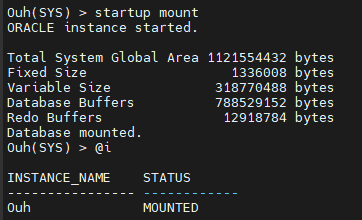
#12. set autorecovery off <------- 복구할 때 적용해야할 로그 파일을 하나씩 물어보게 설정
set autorecovery on <--------복구할 때 아카이브 로그파일을 적용하는거 안물어보고 자동으로 적용되도록하는 명령어
set autorecovery off
#13 . recover database until cancel;
엔터를 치다가 current redo log file을 적용하려할때 cancel 을 입력
<시퀀스번호 확인하고 진행 >

---> 시퀀스번호 7번
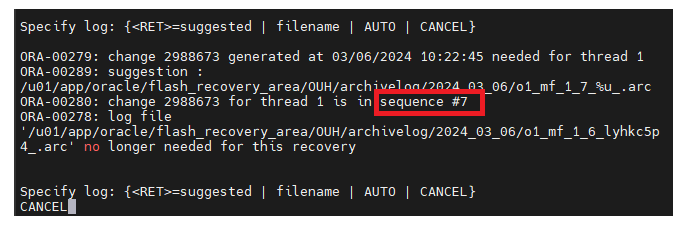

#14. resetlogs 옵션을 써서 open을 시킨다
alter database open resetlogs;
불완전 복구가 끝나면 반드시 coldbackup을 해야한다
문제1. 불완전 복구가 다 했으면 로그 스위치 3번일으키고 체크포인트를 일으킨 후에 coldbackup 하세요
<sys>
shutdown immediate
<os>
cd
mkdir coldbackup5
cd coldbackup5
cp /u01/app/oracle/oradata/Ouh/* .
<sys>
startup
#2. 로그 스위치를 n번 일으키고 체크포인트를 일으킨다(UNUSED가 없도록)
@logsw
@logsw
@logsw
alter system checkpoint
※ 반드시 셧다운immediate하고나서 진행해야한다
문제2. inactive 상태의 redo log file이 손상되었을 때 복구를 진행하세요
#1. 현재 리두로그 그룹의 상태를 확인
#2. shutdown abort
#3. os에서 inactive 상태의 redo log group의 멤버를 모두 삭제
#4. startup <--------mount에서 안올라온다
#5. 리두로그 그룹의 상태를 확인
#6. 문제가 되고 있는 리두 로그 그룹을 drop
#7. db올린다
------
#1. 현재 리두로그 그룹의 상태를 확인
@log_status#2. shutdown abort
#3. os에서 inactive 상태의 redo log group의 멤버를 모두 삭제
#4. startup <--------mount에서 안올라온다
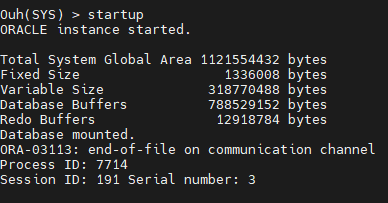
#5. startup mount

#6. 문제가 되고 있는 리두 로그 그룹을 drop
--방법1
alter database drop logfile group 3;
--방법2 (이게 더 좋은방법)
alter database clear unarchived logfile group 3;
#7. db올린다
alter database open;
#8. 새로운 리두로그 그룹을 추가
alter database add logfile group 3 '/u01/app/oracle/oradata/Ouh/redo03.log' size 10m;
alter database add logfile member '/u01/app/oracle/oradata/Ouh/redo03b.log' to group 3;