
Database초보우낙
27. DBA의 DB관리 문서 생성을 파이썬으로 쉽게 구현하 본문
comment on table emp is '부서에 대한 정보를 담고있는 테이블' ;
select *
from all_tab_comments
where table_name='DEPT' and owner='SCOTT';lab128 에 접속하기
sqldeveloper에 scott으로 접속하기
emp 테이블에 대한 설명이 있는 all_tab_comments 를 조회하시오 !
select *
from all_tab_comments
where table_name='EMP' and owner='SCOTT';

EMP 테이블에 대한 설명을 데이터베이스에 저장하세요
comment on table emp is '사원에 대한 정보를 담고있는 테이블' ;
select *
from all_tab_comments
where table_name='EMP' and owner='SCOTT';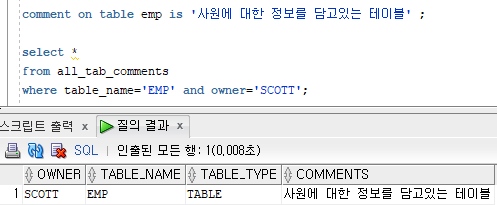
DEPT 테이블에 대한 설명을 데이터베이스에 저장하세요
comment on table DEPT is '사원에 대한 정보를 담고있는 테이블' ;
select *
from all_tab_comments
where table_name='EMP' and owner='SCOTT';
컬럼에 주석다는 SQL
comment on column emp.empno is '사원번호' ;
comment on column emp.ename is '사원이름' ;
comment on column emp.sal is '월급' ;
comment on column emp.job is '직업' ;
comment on column emp.mgr is '관리자 번호' ;
comment on column emp.hiredate is '입사일' ;
comment on column emp.comm is '커미션' ;
comment on column emp.deptno is '부서번호' ;
select *
from all_col_comments
where table_name='EMP' AND OWNER='SCOTT';
EMP 와 DEPT 와 Salgrade 테이블에 대해서 모두 테이블 설명과 컬럼 설명을 입력하세요
-- 예제. EMP 테이블에 대해서 테이블 정의서를 출력하는 SQL을 수행하시오
COMMENT ON TABLE EMP IS '사원 테이블';
COMMENT ON COLUMN EMP.EMPNO IS '사원번호';
COMMENT ON COLUMN EMP.DEPTNO IS '부서번호';
COMMENT ON COLUMN EMP.ENAME IS '사원명';
COMMENT ON COLUMN EMP.JOB IS '직업';
COMMENT ON COLUMN EMP.MGR IS '관리자의 사원번호';
COMMENT ON COLUMN EMP.HIREDATE IS '고용일자';
COMMENT ON COLUMN EMP.SAL IS '월급';
COMMENT ON COLUMN EMP.COMM IS '커미션';
COMMENT ON TABLE DEPT IS '부서 테이블';
COMMENT ON COLUMN DEPT.DEPTNO IS '부서번호';
COMMENT ON COLUMN DEPT.LOC IS '부서위치';
COMMENT ON COLUMN DEPT.DNAME IS '부서명';
COMMENT ON TABLE SALGRADE IS '급여 테이블';
COMMENT ON COLUMN SALGRADE.GRADE IS '급여등급';
COMMENT ON COLUMN SALGRADE.LOSAL IS '최저월급';
COMMENT ON COLUMN SALGRADE.HISAL IS '최고월급';
SELECT A.COLUMN_ID AS NO
, B.COMMENTS AS "논리명"
, A.COLUMN_NAME AS "물리명"
, A.DATA_TYPE AS "자료 형태"
, A.DATA_LENGTH AS "길이"
, DECODE(A.NULLABLE, 'N', 'No', 'Y', 'Yes') AS "Null 허용"
, A.DATA_DEFAULT AS "기본값"
, B.COMMENTS AS "코멘트"
FROM ALL_TAB_COLUMNS A
LEFT JOIN ALL_COL_COMMENTS B
ON A.OWNER = B.OWNER
AND A.TABLE_NAME = B.TABLE_NAME
AND A.COLUMN_NAME = B.COLUMN_NAME
WHERE A.TABLE_NAME = 'EMP' AND A.OWNER='SCOTT'
ORDER BY A.COLUMN_ID;
아래의 출력 결과에서 $ 가 포함된 테이블명은 제외하고 출력하시오
select table_name
from dba_tables
where owner in ('SCOTT', 'HR','SH', 'OE')
and table_name not like 'DM%'
and table_name not like '%$%';
오라클과 연동하는 파이썬코드를 쥬피터에서 실행합니다.
import cx_Oracle
import pandas as pd
# 파이썬에서 오라클로 접속하기 위한 정보를 구성
dsn = cx_Oracle.makedsn('192.168.19.3',8081,'orcl')
db = cx_Oracle.connect('system','oracle_4U',dsn)
cursor=db.cursor() # 오라클의 데이터를 올리기 위한 메모리 구성
cursor.execute("""select t.tablespace_name,
((t.total_size - f.free_size) / t.total_size) * 100 usedspace
from (select tablespace_name, sum(bytes)/1024/1024 total_size
from dba_data_files
group by tablespace_name) t,
(select tablespace_name, sum(bytes)/1024/1024 free_size
from dba_free_space
group by tablespace_name) f
where t.tablespace_name = f.tablespace_name(+)""") # 쿼리수행문의 결과를
# 메모리로 올린다.
row = cursor.fetchall() # 메모리의 데이터를 row 변수에 담는다
ts = pd.DataFrame(row) # row 에 담긴 값을 emp 테이블로 구성
colname = cursor.description
col=[] # col 이라는 비어있는 리스트를 생성합니다.
for i in colname: #colname 리스트 변수에 값을 하나씩 불러와서 i 에 담습니다.
col.append( i[0].lower() ) # i변수에 첫번째 요소를 소문자로 변경해서 col리스트에
ts = pd.DataFrame(list(row), columns=col) # row에 담긴 emp 데이터를 가지고
ts # 판다스 데이터 프레임을 생성하는데 컬럼명을 col 변수에 담긴 컬럼명으로 생성합니다. # 추가합니다.
emp 테이블의 정의서를 출력하는 파이썬코드
import cx_Oracle
import pandas as pd
# 파이썬에서 오라클로 접속하기 위한 정보를 구성
dsn = cx_Oracle.makedsn('192.168.19.3',8081,'orcl')
db = cx_Oracle.connect('system','oracle_4U',dsn)
cursor=db.cursor() # 오라클의 데이터를 올리기 위한 메모리 구성
cursor.execute("""SELECT A.COLUMN_ID AS NO
, B.COMMENTS AS "논리명"
, A.COLUMN_NAME AS "물리명"
, A.DATA_TYPE AS "자료 형태"
, A.DATA_LENGTH AS "길이"
, DECODE(A.NULLABLE, 'N', 'No', 'Y', 'Yes') AS "Null 허용"
, A.DATA_DEFAULT AS "기본값"
, B.COMMENTS AS "코멘트"
FROM ALL_TAB_COLUMNS A
LEFT JOIN ALL_COL_COMMENTS B
ON A.OWNER = B.OWNER
AND A.TABLE_NAME = B.TABLE_NAME
AND A.COLUMN_NAME = B.COLUMN_NAME
WHERE A.TABLE_NAME = 'EMP' AND A.OWNER='SCOTT'
ORDER BY A.COLUMN_ID""") # 쿼리수행문의 결과를
# 메모리로 올린다.
row = cursor.fetchall() # 메모리의 데이터를 row 변수에 담는다
ts = pd.DataFrame(row) # row 에 담긴 값을 emp 테이블로 구성
colname = cursor.description
col=[] # col 이라는 비어있는 리스트를 생성합니다.
for i in colname: #colname 리스트 변수에 값을 하나씩 불러와서 i 에 담습니다.
col.append( i[0].lower() ) # i변수에 첫번째 요소를 소문자로 변경해서 col리스트에
ts = pd.DataFrame(list(row), columns=col) # row에 담긴 emp 데이터를 가지고
ts # 판다스 데이터 프레임을 생성하는데 컬럼명을 col 변수에 담긴 컬럼명으로 생성합니다. # 추가합니다.
파이썬 함수 생성 문법
def f1(x):
a = x + 2
return(a)
print(f1(2))
코드를 함수로 생성했을때의 장점? 재사용이 가능하다.
진짜 유용한 코드 = 평생 사용할 수 있는 코드
def table_def(table_name):
import cx_Oracle
import pandas as pd
# Connection details
dsn = cx_Oracle.makedsn('192.168.19.14', 8081, 'orcl')
db = cx_Oracle.connect('system', 'oracle_4U', dsn)
cursor = db.cursor()
# Execute SQL query
query = f"""
SELECT A.COLUMN_ID AS NO
, B.COMMENTS AS "논리명"
, A.COLUMN_NAME AS "물리명"
, A.DATA_TYPE AS "자료형태"
, A.DATA_LENGTH AS "길이"
, DECODE(A.NULLABLE, 'N', 'No', 'Y', 'Yes') AS "Null허용"
, A.DATA_DEFAULT AS "기본값"
FROM ALL_TAB_COLUMNS A
LEFT JOIN ALL_COL_COMMENTS B
ON A.OWNER = B.OWNER
AND A.TABLE_NAME = B.TABLE_NAME
AND A.COLUMN_NAME = B.COLUMN_NAME
WHERE A.TABLE_NAME = :tbl_name AND A.OWNER = 'SCOTT'
ORDER BY A.COLUMN_ID
"""
cursor.execute(query, tbl_name=table_name.upper())
# Fetch data and metadata for column names
rows = cursor.fetchall()
columns = [col[0] for col in cursor.description] # Get column names from description
# Create DataFrame with correct column names
df = pd.DataFrame(rows, columns=columns)
cursor.close() # It's good practice to close cursor and connection
db.close()
return df
# Example usage:
# df = table_def('EMP')
# print(df)--> 실행했을때 아무것도 안나온다
table_def라는 함수를 만들었고 그 안에 테이블명을 입력하면 테이블의 정의서가 나온다
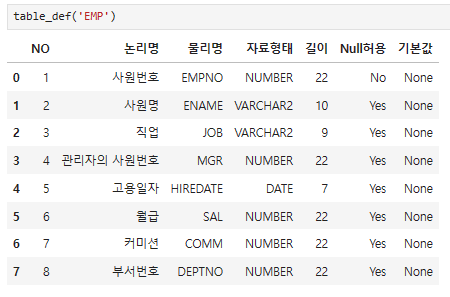
table_list = ['EMP', 'DEPT', 'SALGRADE']
for i in table_list:
df = table_def(i)
print(df)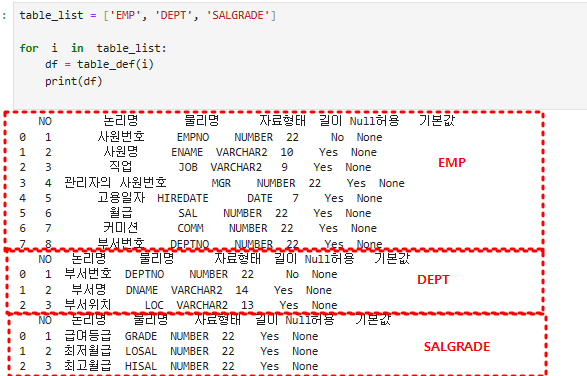
table_list = ['EMP', 'DEPT', 'SALGRADE']
for i in table_list:
df = table_def(i)
output_path=f"c:\\aaa2\\{i}_df.xlsx"
df.to_excel(output_path)
print('Excel 파일 생성이 완료되었습니다')
database 의 hr, sh, oe , scott 계정이 가지고 있는 모든 테이블들에 대해서 테이블 정의서를 생성할 수 있도록 하나의 리스트에 모든 테이블명을 담으시오
import cx_Oracle
import pandas as pd
# 파이썬에서 오라클로 접속하기 위한 정보를 구성
dsn = cx_Oracle.makedsn('192.168.19.14',8081,'orcl')
db = cx_Oracle.connect('system','oracle_4U',dsn)
cursor=db.cursor() # 오라클의 데이터를 올리기 위한 메모리 구성
cursor.execute("""select table_name
from dba_tables
where owner in ('SCOTT', 'HR','SH', 'OE')
and table_name not like 'DM%'
and table_name not like '%$%'""") # 쿼리수행문의 결과를
# 메모리로 올린다.
row = cursor.fetchall() # 메모리의 데이터를 row 변수에 담는다
ts = pd.DataFrame(row) # row 에 담긴 값을 emp 테이블로 구성
colname = cursor.description
col=[] # col 이라는 비어있는 리스트를 생성합니다.
for i in colname: #colname 리스트 변수에 값을 하나씩 불러와서 i 에 담습니다.
col.append( i[0].lower() ) # i변수에 첫번째 요소를 소문자로 변경해서 col리스트에
ts = pd.DataFrame(list(row), columns=col) # row에 담긴 emp 데이터를 가지고
ts # 판다스 데이터 프레임을 생성하는데 컬럼명을 col 변수에 담긴 컬럼명으로 생성합니다. # 추가합니다.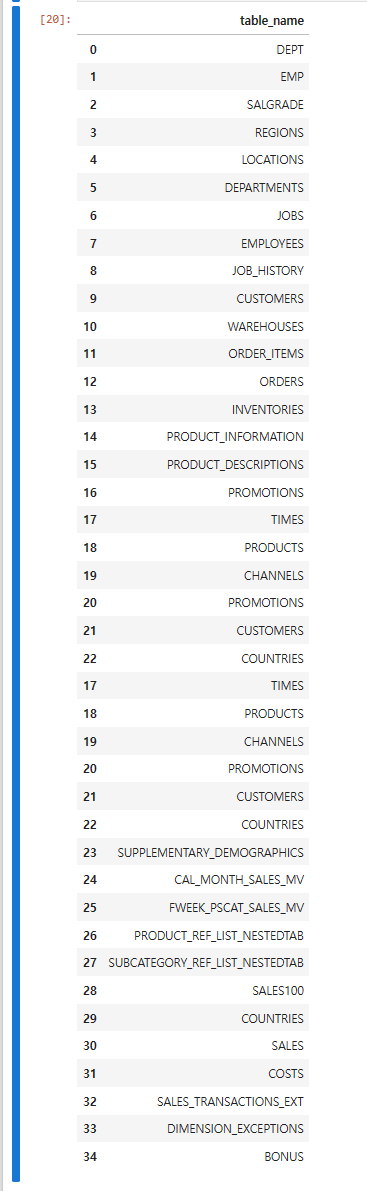
문제.(이수자 평가테이블 정의서가 테이블마다 별도로 생성되는게 아니라 하나의 엑셀 파일로 생성되고 쉬트명이 테이블명으로 생성되게 하시오 !
import cx_Oracle
import pandas as pd
def table_def(table_name, cursor):
# Execute SQL query
query = """
SELECT A.COLUMN_ID AS NO
, B.COMMENTS AS "논리명"
, A.COLUMN_NAME AS "물리명"
, A.DATA_TYPE AS "자료형태"
, A.DATA_LENGTH AS "길이"
, DECODE(A.NULLABLE, 'N', 'No', 'Y', 'Yes') AS "Null허용"
, A.DATA_DEFAULT AS "기본값"
FROM ALL_TAB_COLUMNS A
LEFT JOIN ALL_COL_COMMENTS B
ON A.OWNER = B.OWNER
AND A.TABLE_NAME = B.TABLE_NAME
AND A.COLUMN_NAME = B.COLUMN_NAME
WHERE A.TABLE_NAME = :tbl_name
ORDER BY A.COLUMN_ID
"""
cursor.execute(query, tbl_name=table_name.upper())
# Fetch data and metadata for column names
rows = cursor.fetchall()
columns = [col[0] for col in cursor.description] # Get column names from description
# Create DataFrame with correct column names
df = pd.DataFrame(rows, columns=columns)
return df
# Connection details
dsn = cx_Oracle.makedsn('192.168.19.14', 8081, 'orcl')
db = cx_Oracle.connect('system', 'oracle_4U', dsn)
cursor = db.cursor() # Prepare cursor for fetching data
# Fetching table names
cursor.execute("""
SELECT table_name
FROM dba_tables
WHERE owner IN ('SCOTT', 'HR', 'SH', 'OE')
AND table_name NOT LIKE 'DM%'
AND table_name NOT LIKE '%$%'
""")
table_names = [row[0] for row in cursor.fetchall()]
for table_name in table_names:
df = table_def(table_name, cursor)
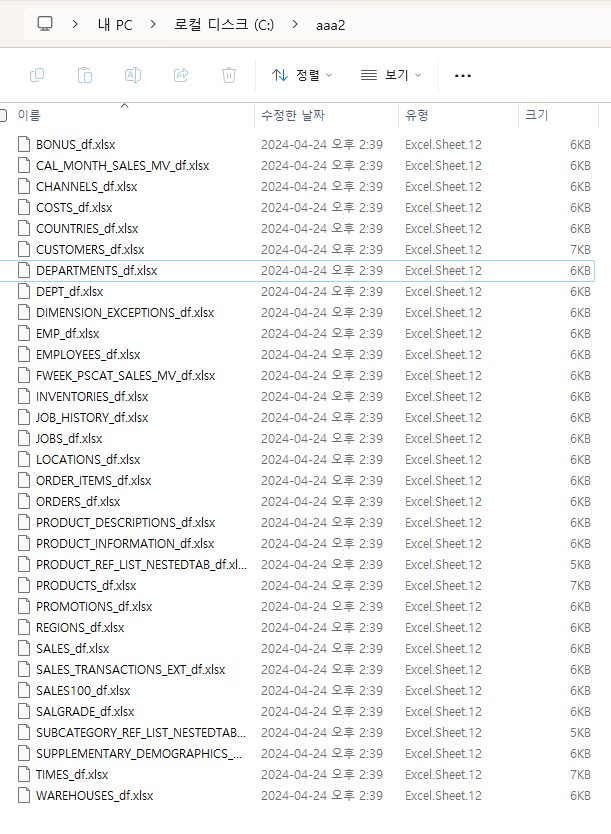
output_path = f"c:\\aaa2\\{table_name}_df.xlsx"
df.to_excel(output_path) # Export DataFrame to an Excel file
print('Excel 파일 생성이 완료되었습니다')
# Close cursor and connection
cursor.close()
db.close()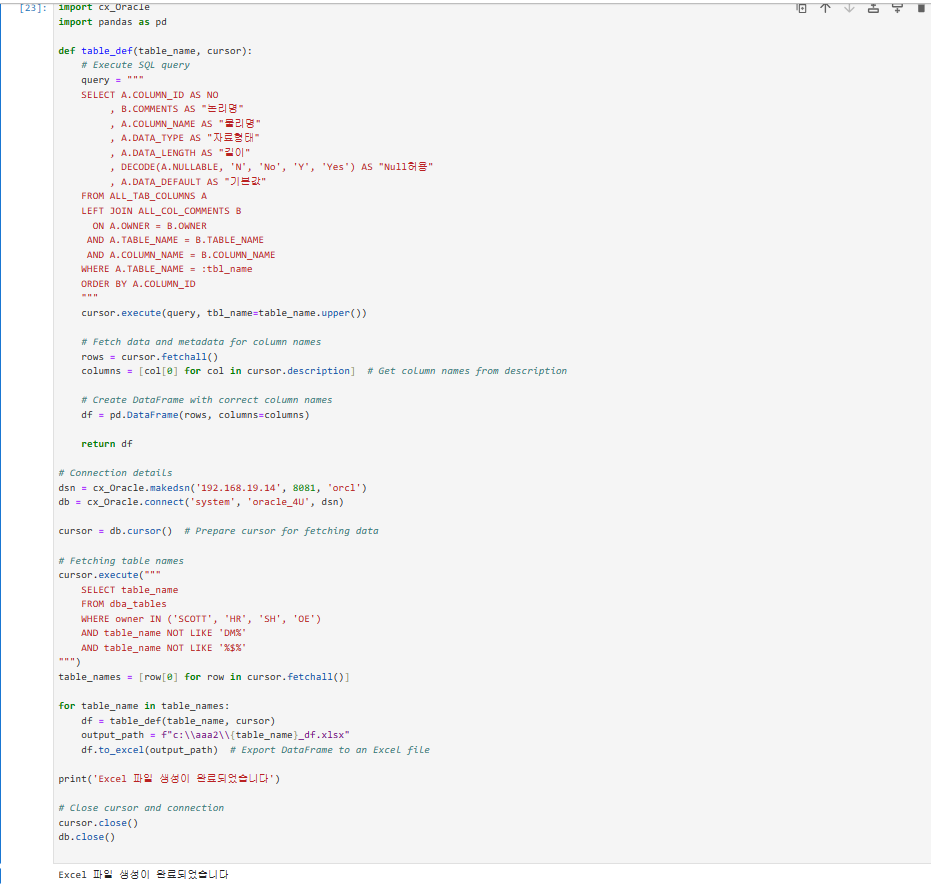
'파이썬' 카테고리의 다른 글
| 28. 테이블 정의서 홈페이지 만들기 (0) | 2024.04.25 |
|---|---|
| 28. 테이블 정의서 홈페이지 만들기 (0) | 2024.04.25 |
| 26. undo tablespace와 temp tablespace의 사용량만 집중적으로 시각화 (0) | 2024.04.22 |
| 25. LAV128 활용하는 팁 2 (0) | 2024.04.22 |
| 24. LAB128 활용팁 (2) | 2024.04.22 |
'파이썬' Related Articles
more



